-
IRIS Example
Goal: Given 150 examples or training set of Iris flowers and three class values we have to build a model to predict the class of new Iris flowers. The features are petal width, petal length, sepal width and sepal length. We will use the K-Nearest Neighbors Algorithm.
Setup and install pre-requisite software
If you are installing with Python 2.7 then:
$ pip install numpy scipy mathplotlib ipython scikit-learn pandas pillow -
If you are installing with Python 3.x then: Make sure you install python 3.x
Use pip3 instead of pip to install the above components as otherwise they will get installed to the 2.7 Library path.
pip3 install numpy scipy mathplotlib ipython scikit-learn pandas pillow
Also install Jupyter and Graphviz
pip3 install --upgrade pip
pip3 install jupyter
pip3 install graphviz
-
Run the Jupyter Notebook
jupyter notebook
This will open up the Jupyter Notebook in your local browser. Take the code in iris.py and paste it in In[1] and run. Note that this code has been tested and modified so that not only does it run in the Jupyter Notebook but also displays the associated graphics using Panda.
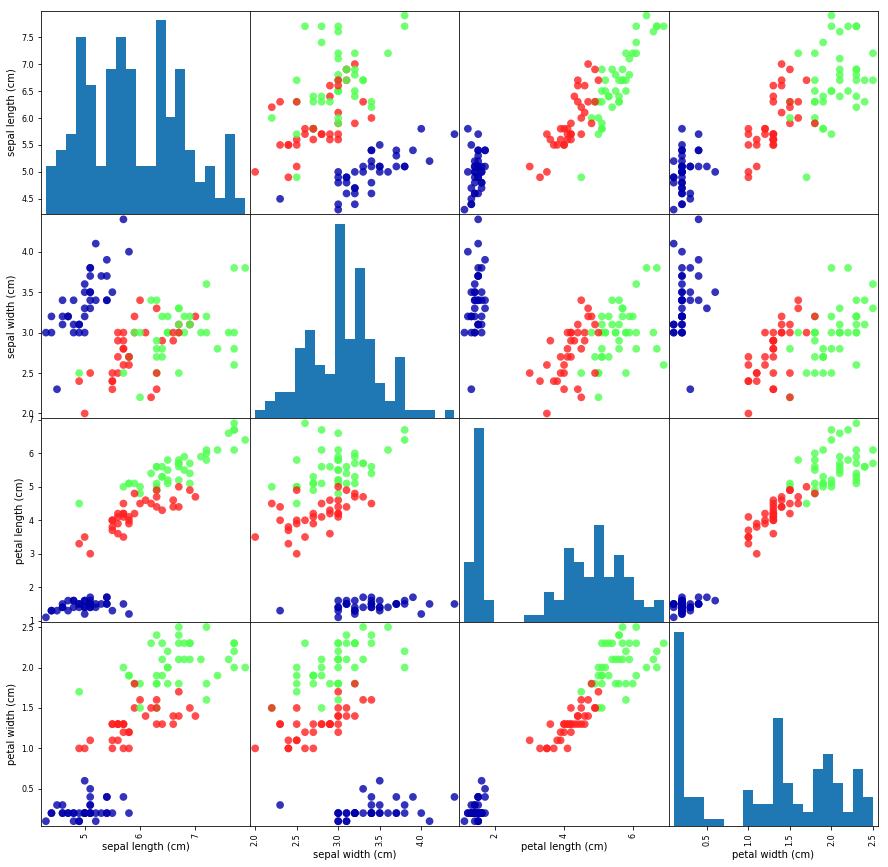
import numpy as np import pandas as pd import mglearn from sklearn.datasets import load_iris %matplotlib inline import matplotlib.pyplot as plt iris_dataset = load_iris() print("Keys of iris_dataset: {}".format(iris_dataset.keys())) print(iris_dataset['DESCR'][:193] + "\n...") print("Target names: {}".format(iris_dataset['target_names'])) print("Feature names: {}".format(iris_dataset['feature_names'])) print("Type of data: {}".format(type(iris_dataset['data']))) print("Shape of data: {}".format(iris_dataset['data'].shape)) print("First five columns of data:\n{}".format(iris_dataset['data'][:150])) print("Type of target: {}".format(type(iris_dataset['target']))) print("Shape of target: {}".format(iris_dataset['target'].shape)) print("Target:\n{}".format(iris_dataset['target'])) print("-----------------") print("Running train_test_split") print("-----------------") from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split( iris_dataset['data'], iris_dataset['target'], random_state=0) print("X_train shape: {}".format(X_train.shape)) print("y_train shape: {}".format(y_train.shape)) print("-----------------") print("X_test shape: {}".format(X_test.shape)) print("y_test shape: {}".format(y_test.shape)) # create dataframe from data in X_train # label the columns using the strings in iris_dataset.feature_names iris_dataframe = pd.DataFrame(X_train, columns=iris_dataset.feature_names) # create a scatter matrix from the dataframe, color by y_train grr = pd.scatter_matrix(iris_dataframe, c=y_train, figsize=(15, 15), marker='o', hist_kwds={'bins': 20}, s=60, alpha=.8, cmap=mglearn.cm3) from sklearn.neighbors import KNeighborsClassifier knn = KNeighborsClassifier(n_neighbors=1) knn.fit(X_train, y_train) X_new = np.array([[5, 2.9, 1, 0.2]]) print("X_new.shape: {}".format(X_new.shape)) prediction = knn.predict(X_new) print("Prediction: {}".format(prediction)) print("Predicted target name: {}".format( iris_dataset['target_names'][prediction])) y_pred = knn.predict(X_test) print("Test set predictions:\n {}".format(y_pred)) print("Test set score: {:.2f}".format(np.mean(y_pred == y_test))) print("Test set score: {:.2f}".format(knn.score(X_test, y_test))) X_train, X_test, y_train, y_test = train_test_split( iris_dataset['data'], iris_dataset['target'], random_state=0) knn = KNeighborsClassifier(n_neighbors=1) knn.fit(X_train, y_train) print("Test set score: {:.2f}".format(knn.score(X_test, y_test)))
Here is the result:
Keys of iris_dataset: dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names']) Iris Plants Database ==================== Notes ----- Data Set Characteristics: :Number of Instances: 150 (50 in each of three classes) :Number of Attributes: 4 numeric, predictive att ... Target names: ['setosa' 'versicolor' 'virginica'] Feature names: ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'] Type of data:Shape of data: (150, 4) First five columns of data: [[ 5.1 3.5 1.4 0.2] [ 4.9 3. 1.4 0.2] [ 4.7 3.2 1.3 0.2] [ 4.6 3.1 1.5 0.2] [ 5. 3.6 1.4 0.2] [ 5.4 3.9 1.7 0.4] [ 4.6 3.4 1.4 0.3] [ 5. 3.4 1.5 0.2] [ 4.4 2.9 1.4 0.2] [ 4.9 3.1 1.5 0.1] [ 5.4 3.7 1.5 0.2] [ 4.8 3.4 1.6 0.2] [ 4.8 3. 1.4 0.1] [ 4.3 3. 1.1 0.1] [ 5.8 4. 1.2 0.2] [ 5.7 4.4 1.5 0.4] [ 5.4 3.9 1.3 0.4] [ 5.1 3.5 1.4 0.3] [ 5.7 3.8 1.7 0.3] [ 5.1 3.8 1.5 0.3] [ 5.4 3.4 1.7 0.2] [ 5.1 3.7 1.5 0.4] [ 4.6 3.6 1. 0.2] [ 5.1 3.3 1.7 0.5] [ 4.8 3.4 1.9 0.2] [ 5. 3. 1.6 0.2] [ 5. 3.4 1.6 0.4] [ 5.2 3.5 1.5 0.2] [ 5.2 3.4 1.4 0.2] [ 4.7 3.2 1.6 0.2] [ 4.8 3.1 1.6 0.2] [ 5.4 3.4 1.5 0.4] [ 5.2 4.1 1.5 0.1] [ 5.5 4.2 1.4 0.2] [ 4.9 3.1 1.5 0.1] [ 5. 3.2 1.2 0.2] [ 5.5 3.5 1.3 0.2] [ 4.9 3.1 1.5 0.1] [ 4.4 3. 1.3 0.2] [ 5.1 3.4 1.5 0.2] [ 5. 3.5 1.3 0.3] [ 4.5 2.3 1.3 0.3] [ 4.4 3.2 1.3 0.2] [ 5. 3.5 1.6 0.6] [ 5.1 3.8 1.9 0.4] [ 4.8 3. 1.4 0.3] [ 5.1 3.8 1.6 0.2] [ 4.6 3.2 1.4 0.2] [ 5.3 3.7 1.5 0.2] [ 5. 3.3 1.4 0.2] [ 7. 3.2 4.7 1.4] [ 6.4 3.2 4.5 1.5] [ 6.9 3.1 4.9 1.5] [ 5.5 2.3 4. 1.3] [ 6.5 2.8 4.6 1.5] [ 5.7 2.8 4.5 1.3] [ 6.3 3.3 4.7 1.6] [ 4.9 2.4 3.3 1. ] [ 6.6 2.9 4.6 1.3] [ 5.2 2.7 3.9 1.4] [ 5. 2. 3.5 1. ] [ 5.9 3. 4.2 1.5] [ 6. 2.2 4. 1. ] [ 6.1 2.9 4.7 1.4] [ 5.6 2.9 3.6 1.3] [ 6.7 3.1 4.4 1.4] [ 5.6 3. 4.5 1.5] [ 5.8 2.7 4.1 1. ] [ 6.2 2.2 4.5 1.5] [ 5.6 2.5 3.9 1.1] [ 5.9 3.2 4.8 1.8] [ 6.1 2.8 4. 1.3] [ 6.3 2.5 4.9 1.5] [ 6.1 2.8 4.7 1.2] [ 6.4 2.9 4.3 1.3] [ 6.6 3. 4.4 1.4] [ 6.8 2.8 4.8 1.4] [ 6.7 3. 5. 1.7] [ 6. 2.9 4.5 1.5] [ 5.7 2.6 3.5 1. ] [ 5.5 2.4 3.8 1.1] [ 5.5 2.4 3.7 1. ] [ 5.8 2.7 3.9 1.2] [ 6. 2.7 5.1 1.6] [ 5.4 3. 4.5 1.5] [ 6. 3.4 4.5 1.6] [ 6.7 3.1 4.7 1.5] [ 6.3 2.3 4.4 1.3] [ 5.6 3. 4.1 1.3] [ 5.5 2.5 4. 1.3] [ 5.5 2.6 4.4 1.2] [ 6.1 3. 4.6 1.4] [ 5.8 2.6 4. 1.2] [ 5. 2.3 3.3 1. ] [ 5.6 2.7 4.2 1.3] [ 5.7 3. 4.2 1.2] [ 5.7 2.9 4.2 1.3] [ 6.2 2.9 4.3 1.3] [ 5.1 2.5 3. 1.1] [ 5.7 2.8 4.1 1.3] [ 6.3 3.3 6. 2.5] [ 5.8 2.7 5.1 1.9] [ 7.1 3. 5.9 2.1] [ 6.3 2.9 5.6 1.8] [ 6.5 3. 5.8 2.2] [ 7.6 3. 6.6 2.1] [ 4.9 2.5 4.5 1.7] [ 7.3 2.9 6.3 1.8] [ 6.7 2.5 5.8 1.8] [ 7.2 3.6 6.1 2.5] [ 6.5 3.2 5.1 2. ] [ 6.4 2.7 5.3 1.9] [ 6.8 3. 5.5 2.1] [ 5.7 2.5 5. 2. ] [ 5.8 2.8 5.1 2.4] [ 6.4 3.2 5.3 2.3] [ 6.5 3. 5.5 1.8] [ 7.7 3.8 6.7 2.2] [ 7.7 2.6 6.9 2.3] [ 6. 2.2 5. 1.5] [ 6.9 3.2 5.7 2.3] [ 5.6 2.8 4.9 2. ] [ 7.7 2.8 6.7 2. ] [ 6.3 2.7 4.9 1.8] [ 6.7 3.3 5.7 2.1] [ 7.2 3.2 6. 1.8] [ 6.2 2.8 4.8 1.8] [ 6.1 3. 4.9 1.8] [ 6.4 2.8 5.6 2.1] [ 7.2 3. 5.8 1.6] [ 7.4 2.8 6.1 1.9] [ 7.9 3.8 6.4 2. ] [ 6.4 2.8 5.6 2.2] [ 6.3 2.8 5.1 1.5] [ 6.1 2.6 5.6 1.4] [ 7.7 3. 6.1 2.3] [ 6.3 3.4 5.6 2.4] [ 6.4 3.1 5.5 1.8] [ 6. 3. 4.8 1.8] [ 6.9 3.1 5.4 2.1] [ 6.7 3.1 5.6 2.4] [ 6.9 3.1 5.1 2.3] [ 5.8 2.7 5.1 1.9] [ 6.8 3.2 5.9 2.3] [ 6.7 3.3 5.7 2.5] [ 6.7 3. 5.2 2.3] [ 6.3 2.5 5. 1.9] [ 6.5 3. 5.2 2. ] [ 6.2 3.4 5.4 2.3] [ 5.9 3. 5.1 1.8]] Type of target: Shape of target: (150,) Target: [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2] ----------------- Running train_test_split ----------------- X_train shape: (112, 4) y_train shape: (112,) ----------------- X_test shape: (38, 4) y_test shape: (38,) /Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/ipykernel_launcher.py:35: FutureWarning: pandas.scatter_matrix is deprecated. Use pandas.plotting.scatter_matrix instead X_new.shape: (1, 4) Prediction: [0] Predicted target name: ['setosa'] Test set predictions: [2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 1 0 0 2 0 0 1 1 0 2 1 0 2 2 1 0 2] Test set score: 0.97 Test set score: 0.97 Test set score: 0.97